|
|
| Line 49: |
Line 49: |
| [[File:2023 Word Match - 2023 01 How To 01 Setup 03.png]] | | [[File:2023 Word Match - 2023 01 How To 01 Setup 03.png]] |
|
| |
|
| === Changing the N-Gram === | | === Adding a Lexicon === |
|
| |
|
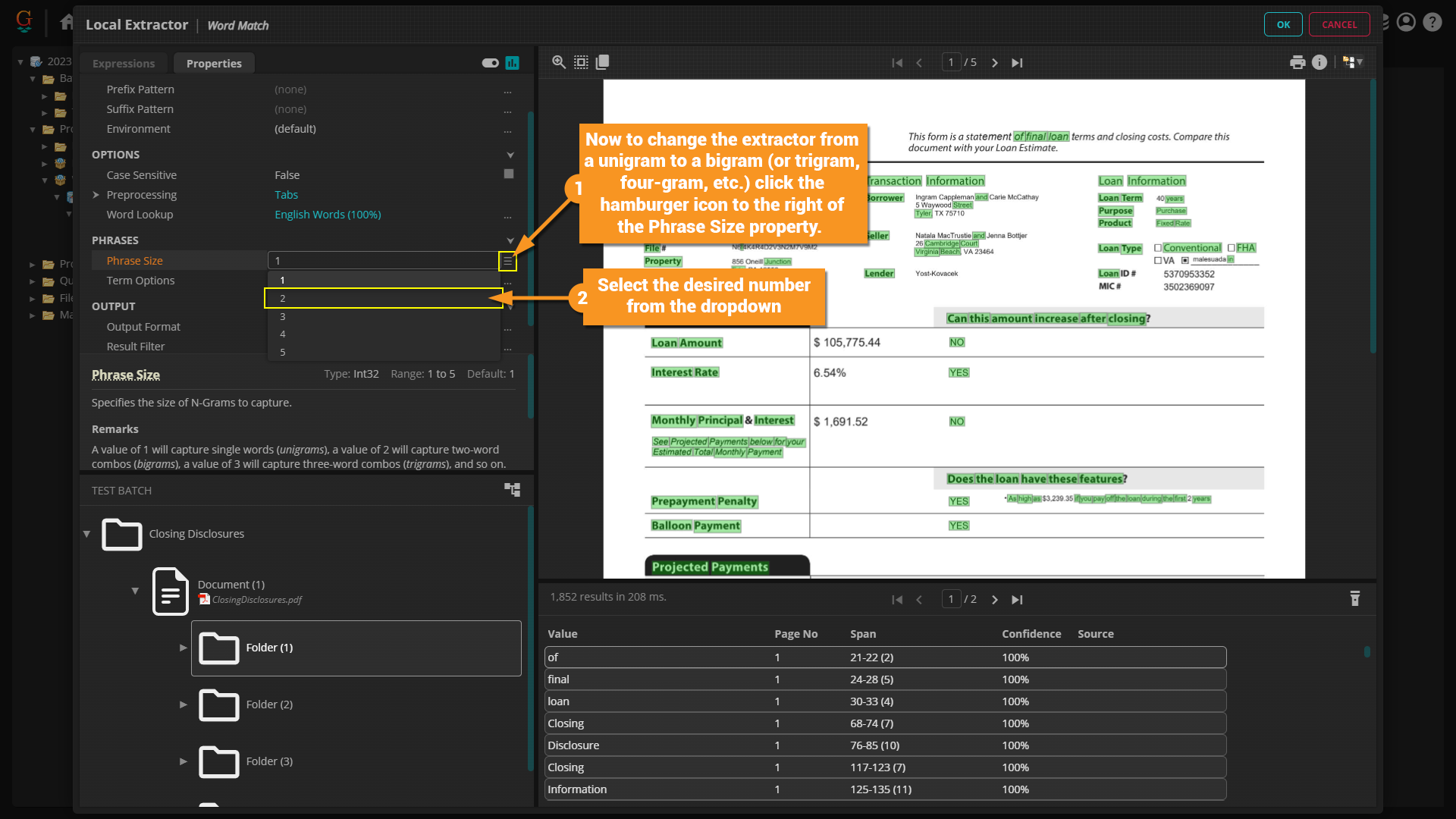
| By default the ''Word Match'' extractor collects single words or unigrams and often collects "words" that aren't actually in the English language. Let's say you want to change this to bigrams and only want to collect words that are included in the Engish dictionary.
| | You can add a '''Lexicon''' to a ''Word Match'' to aid in extraction. ''Word Match'' often collects "words" that aren't actually in the English language. Let's say you want to change to to only collect words that are included in the Engish dictionary. |
|
| |
|
|
| |
|
| [[File:2023 Word Match - 2023 01 How To 02 Changing the N-Gram 01.png]] | | [[File:2023 Word Match - 2023 01 How To 02 Changing the N-Gram 01.png]] |
| | |
| | === Changing the N-Gram === |
| | |
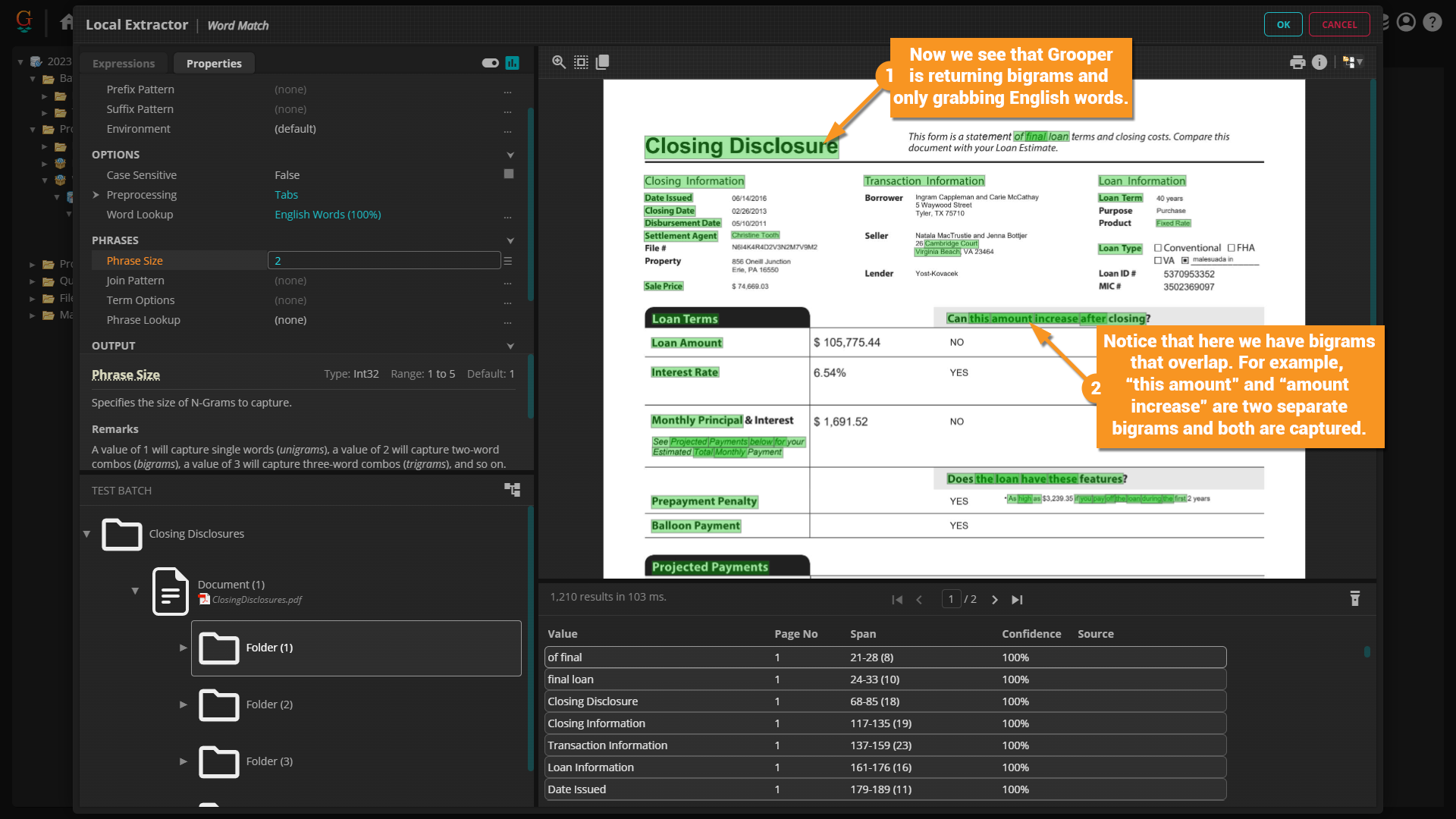
| | By default the ''Word Match'' extractor collects single words or unigrams. Let's say you want to change this to bigrams, trigrams, four-grams, etc. We can do this from the "Properties" tab on the extractor window. |
|
| |
|
|
| |
|
| Line 61: |
Line 65: |
|
| |
|
| [[File:2023 Word Match - 2023 01 How To 02 Changing the N-Gram 03.png]] | | [[File:2023 Word Match - 2023 01 How To 02 Changing the N-Gram 03.png]] |
|
| |
| <!--
| |
| You can enter '''''Prefix''''' and '''''Suffix Patterns''''' to only return an n-gram if a regex pattern ''also'' matches before or after. These are useful for anchoring the n-gram you want to return next to some other piece of text. For example, a '''''Prefix Pattern''''' of <code>\n</code> could be used to ''only'' return n-grams at the start of a new line because the <code>\n</code> character precedes every new line in the text data. Furthermore, ''only'' the n-gram is returned, not the text matched by the '''''Prefix''''' and '''''Suffix Patterns'''''.
| |
|
| |
| The '''''Join Pattern''''' property is unique to the ''Word Match'' extractor. This determines how terms of bigrams, trigrams, four-grams, and five-grams can be joined. Most often, terms (or grams) are simply joined by a single space, as in the bigram "''first second''". If you leave this property blank, Grooper will assume n-grams are always separated by a single space. However, you may want to include n-grams that are separated by other characters. For example hyphenated words, as in "''first-second''". The '''''Join Pattern''''' allows you to enter a regular expression for the allowable characters between two grams. For example, a '''''Join Pattern''''' of <code>[ -]</code> would allow for a single space or hyphen to be between each term, matching "''first second''" as well as "''first-second''".
| |
|
| |
| The '''''Output Format''''' allows you to alter the output result for data cleansing or other purposes.
| |
|
| |
| The "Properties" tab allows you to further configure the n-gram matching. Most importantly, the n-gram size is set here as well as any '''Lexicon''' used to lookup against the returned values. You can also enable Tab Marking, Fuzzy RegEx mode, filter results based on page location, determine case sensitivity, and more.
| |
|
| |
| {|cellpadding=10 cellpadding=5
| |
| |valign=top style="width:40%"|
| |
| In this example, a '''Value Reader''' is configured to return bigram field labels, using the ''Word Match'' '''''Extractor Type'''''.
| |
|
| |
| # ''Word Match'' is selected as the '''''Extractor Type'''''
| |
| # The '''''Word Pattern''''' is entered here.
| |
| #* The regex pattern entered here is used to match each single gram in the n-gram. The default pattern <code>\p{L}+</code> matches any combination of letter characters in any language of any length. In most cases, this pattern will perfectly suit your n-gram extraction needs. However, you can alter this pattern if you need. For example, <code>[a-zA-Z]+</code> is a very similar pattern that could be used to match English only words, as it does not include characters of foreign scripts. For example, it would not match Greek characters, such as Ω, where <code>\p{L}+</code> would.
| |
| # The '''''Prefix Pattern''''' is entered here.
| |
| #* In this case, the pattern entered will only match n-grams if they are preceded by a <code>\n</code> <code>\t</code> or beginning of string <code>^</code> character.
| |
| # The '''''Suffix Pattern''''' is entered here.
| |
| #* In this case, the pattern entered will only match n-grams if they are followed by a <code>\r</code> <code>\t</code> or end of string <code>$</code> character.
| |
| # The '''''Join Pattern''''' is entered here.
| |
| #* The pattern here, <code>[ \-]</code> will return n-grams whos grams are separated by a single space character, a backspace, or a hyphen. If left blank, only n-grams whose grams are separated by a single space character are returned.
| |
| # The '''''Output Format''''' is formatted here.
| |
| #* Unused in this example.
| |
| |
| |
| [[File:Value-reader-extractor-types-05.png]]
| |
| |-
| |
| |valign=top|
| |
| In this case, we also used the "Properties" tab to set the n-gram size to collect bigrams, and only return grams in a English language dictionary.
| |
|
| |
| # Navigate to the "Properties" tab.
| |
| # The '''''Word Lookup''''' property can be used to reference a '''Lexicon''' of allowable terms for each gram in the n-gram.
| |
| #* Here, we reference the "English Words" '''Lexicon''' that ships with every Grooper install in the "Essentials" folder of the '''Global Resources''' folder.
| |
| # The '''''Phrase Size''''' property allows you to specify the size of the n-gram.
| |
| #* Here, it is set to ''2'' to capture bigrams.
| |
| |
| |
| [[File:Value-reader-extractor-types-06.png]]
| |
| |}
| |
|
| |
|
| |
| {|cellpadding="10" cellspacing="5"
| |
| |-style="background-color:#36b0a7; color:white"
| |
| |style="font-size:14pt"|'''FYI'''||Prior to Grooper version 2021, n-gram extraction configuration was lumped into other regular expression pattern configurations. As with the ''Pattern Match'' extractor, this was delivered in one of two ways:
| |
|
| |
| :1. By the '''Data Format''' object.
| |
| :2. Configuring extractor properties and selecting ''Internal'' or ''Text Pattern'' as the extractor type.
| |
|
| |
| Each of these methods used a "Pattern Editor" UI screen to configure a regular expression. The n-gram size and referenced term lexicons were set in the "Properties" tab. In version 2021, the '''Data Format''' object and the ''Internal'' and ''Text Pattern'' extractor types are gone. The ''Word Match'' extractor replaces their functionality to return n-grams in an effort to simplify n-gram extraction setup and distinguish it from general regex pattern matching.
| |
| |}
| |
|
WIP
|
This article is a work-in-progress or created as a placeholder for testing purposes. This article is subject to change and/or expansion. It may be incomplete, inaccurate, or stop abruptly.
This tag will be removed upon draft completion.
|
The Word Match is an Extractor Type found in Grooper. This extractor is designed to collect full words and is often used in n-gram extraction.
About
The Word Match extractor is designed for n-gram extraction. An n-gram is "a contiguous sequence of n items from a given sample of text or speech." [1] Typically in Grooper, this refers to extracting words or phrases from a lexicon of terms.
Grooper generally uses n-grams for the purpose of feature collection for Lexical Classification. The Word Match extractor can capture 1-grams (single words) up to 5-grams (five word phrases). Lexicons are commonly used to dictate a dictionary of allowable returned words. This could be general Lexicon of common English words or a custom Lexicon, such as one with industry specific terms.
| FYI
|
An n-gram is often referred to by a different name depending its n size.
- 1-grams (single words) - unigrams
- 2-grams (word pairs) - bigrams
- 3-grams (three word phrases) - trigrams
- 4-grams (four word phrases) - four-grams
- 5-grams (five word phrases) - five-grams
As an additional FYI, four-grams are not called "tetragrams" because the term already has usage as a single word consisting of four letters or characters. "Quadrigram" is occasionally used, but four-gram is the more common terminology. Five-grams are not called "pentagrams", because that already has common usage for a geometric figure.
|
How To
Setup
First, let's set the Word Match extractor on a Data Type.
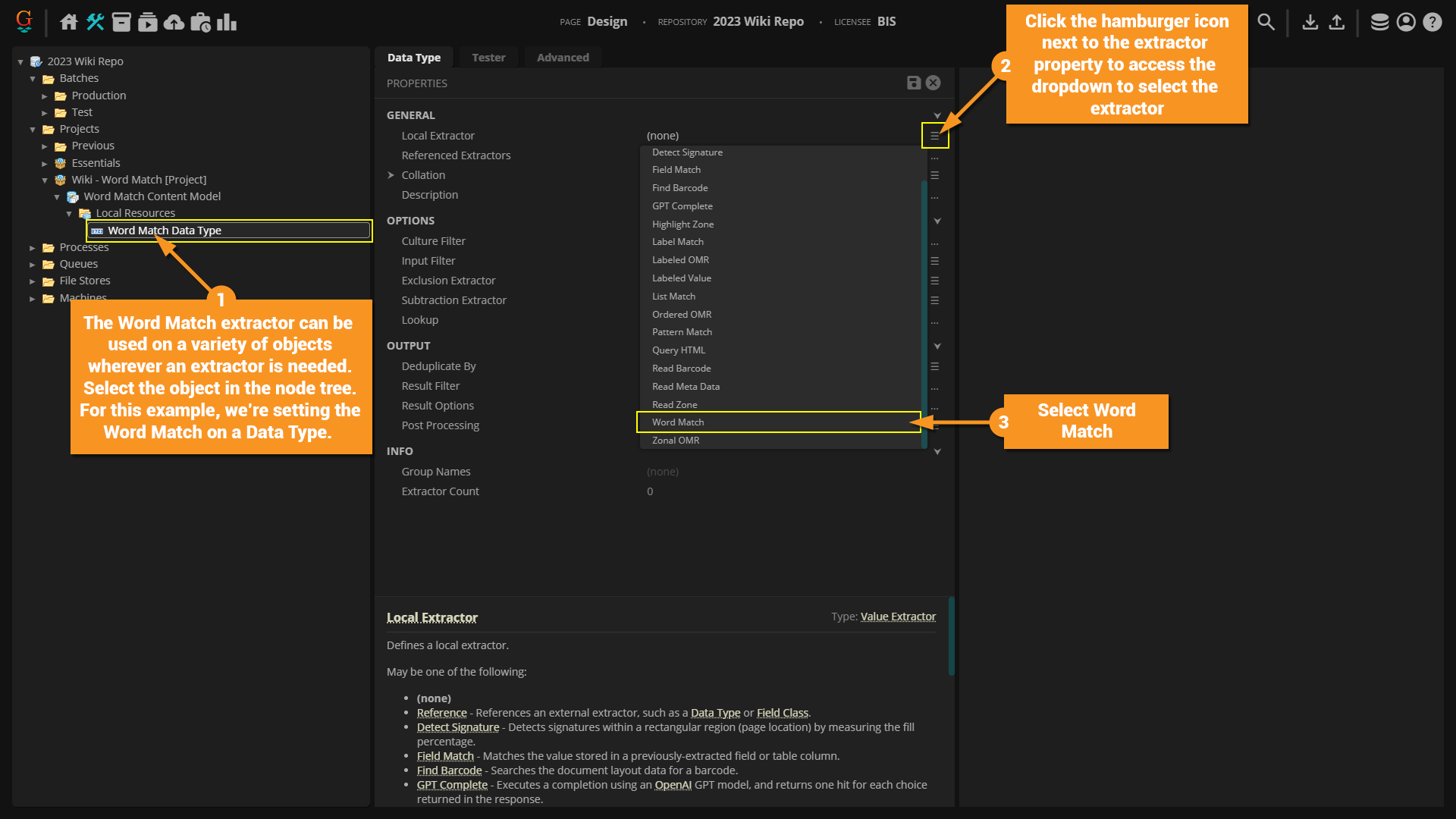
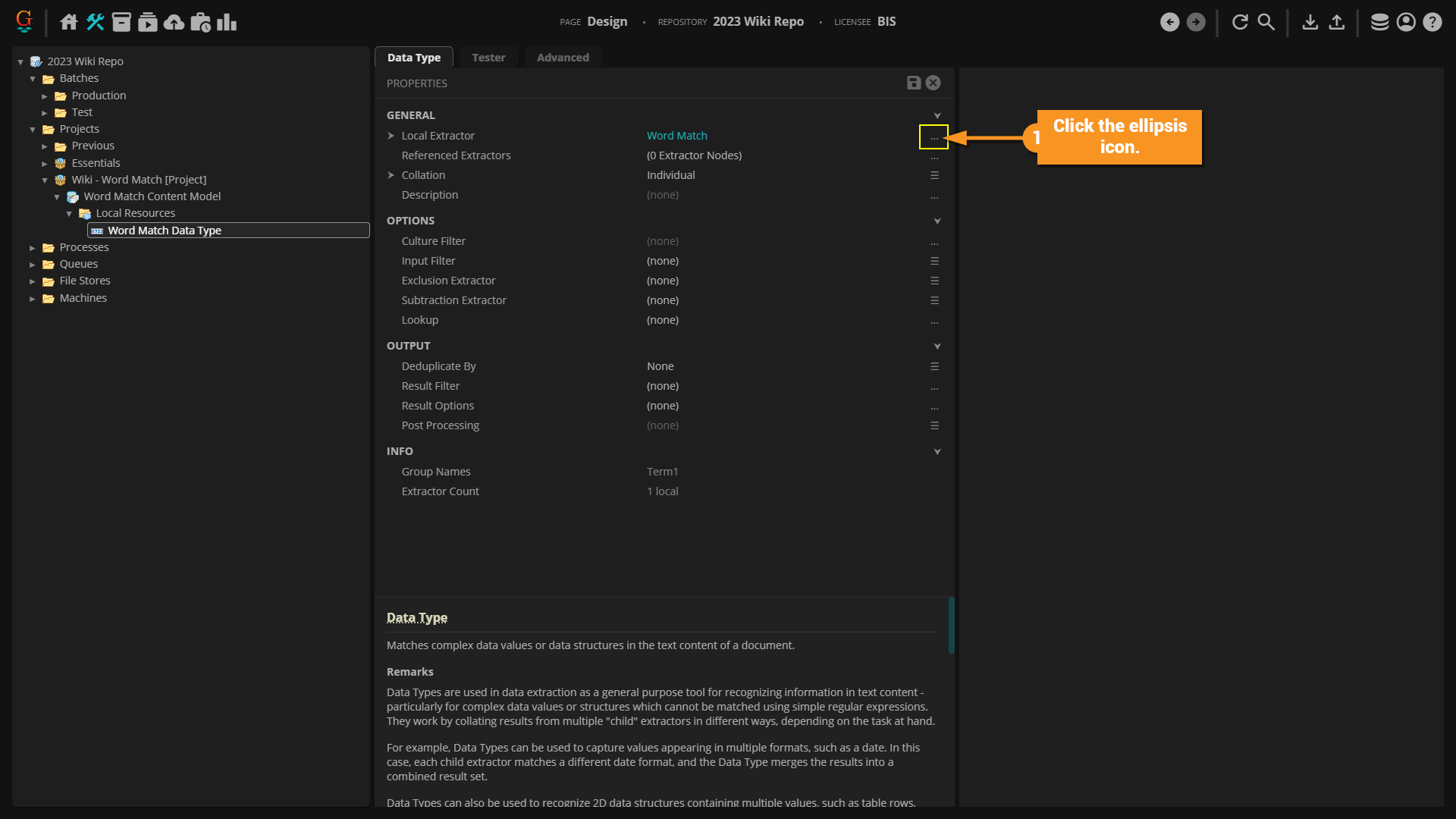
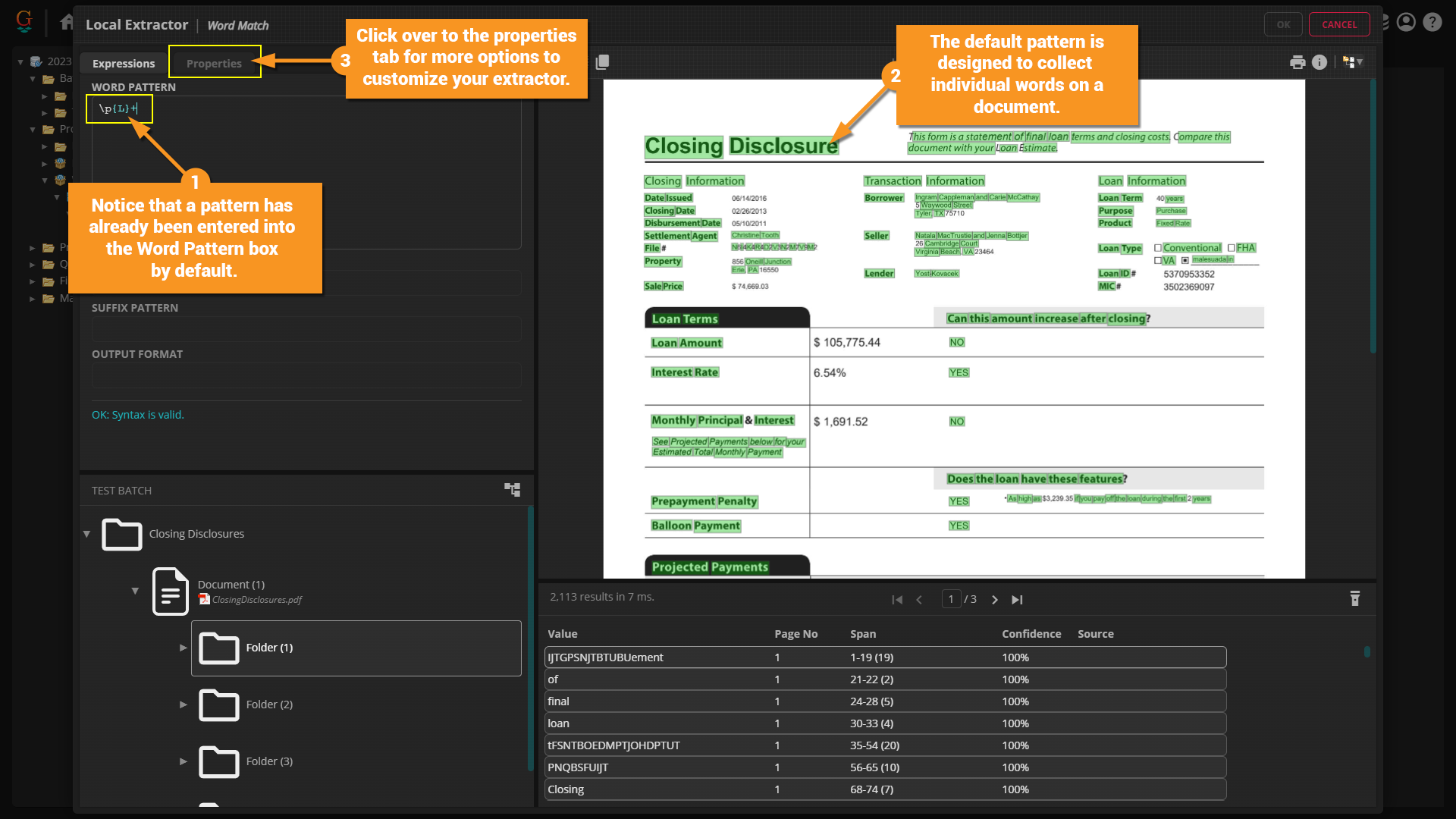
Adding a Lexicon
You can add a Lexicon to a Word Match to aid in extraction. Word Match often collects "words" that aren't actually in the English language. Let's say you want to change to to only collect words that are included in the Engish dictionary.
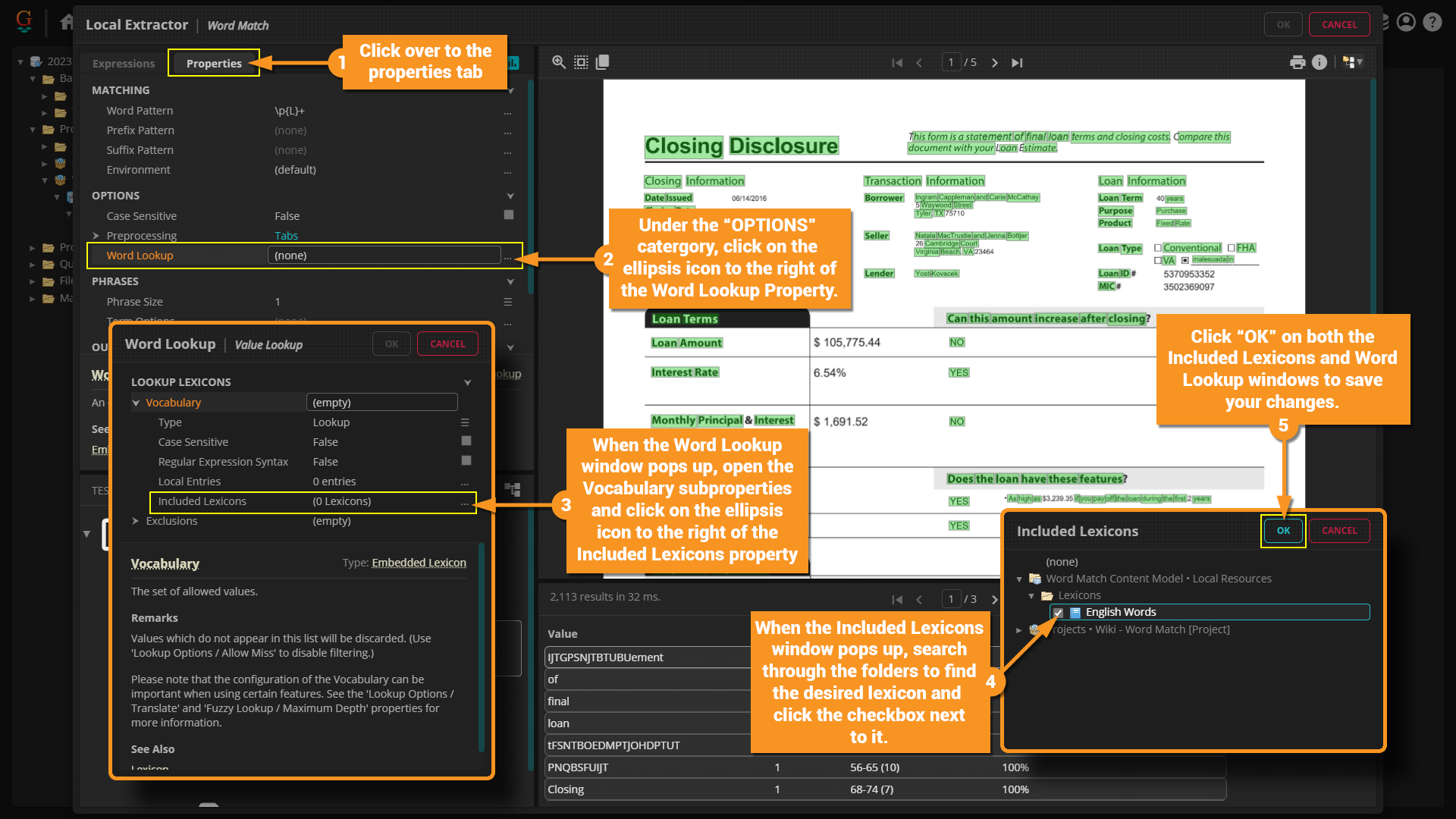
Changing the N-Gram
By default the Word Match extractor collects single words or unigrams. Let's say you want to change this to bigrams, trigrams, four-grams, etc. We can do this from the "Properties" tab on the extractor window.