
Main Page: Difference between revisions
Dgreenwood (talk | contribs) No edit summary |
Dgreenwood (talk | contribs) No edit summary |
||
| Line 21: | Line 21: | ||
|-style="background-color:#d8f3f1" valign="top" | |-style="background-color:#d8f3f1" valign="top" | ||
| | | | ||
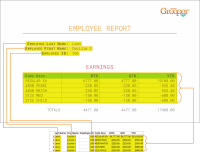
[[ | [[File:separation_and_review_14.png|right|500px|link=Separation and Separation Review|This is an example of the '''Separation Review''' '''Attended Client''' interface.]] | ||
<blockquote style="font-size:14pt"> | |||
'''[[Separation and Separation Review]]''' | |||
</blockquote> | |||
'''Grooper''' uses various approaches and '''[https://en.wikipedia.org/wiki/Algorithm algorithms]''' to determine the classification of a page or folder. The settings on a '''[[Content Model]]''' and '''[[Document Type]]''' add to the complexities for separating pages into documents. Grooper Version 2.9 builds on the '''''Separation''''' settings found on '''Document Types''', including the ability to adjust the '''''Training Scope''''' and configure a '''''Secondary Page Extractor'''''. | |||
Adjusting the '''Training Scope''' provides benefits to the accuracy and performance of '''ESP Auto Separation''' by focusing what is important when it comes time to separate and classify ''Unstructured'' paginated documents. For example, the ''Normal'' mode will create a single '''FormType''' and divide trained examples into "First", "Middle" and "Last" pages. From individual document to individual document, often the most meaningful features composing them are found on the first and last pages, and there can be more variance on the pages in between. This is different from the previous approach, which created individual '''FormTypes''' for each trained example, each with their own "Page X of X" '''PageType''' objects. This unifies all trained examples into a single '''FormType''', making the training and classification of these documents ultimately simpler and more efficient. The ''FirstLast'' mode assumes meaningful features for classification are ''only'' found on the first and last pages, with the middle pages containing no information needed to make a separation or classification decision. With this mode enabled, ''only'' trained examples of the first and last page and their associated features will be saved. This can improve processing time by removing all the features in the middle pages for consideration. The ''FirstOnly'' mode narrows this scope even further by only storing features from the first page of trained documents. | |||
Furthermore, ESP Auto Separation ''removes'' but does not ''eliminate'' a lot of the manual work to separate and classify documents. Separation Review is a new review module designed to make the manual work quick and easy. | |||
For more information on | For more information on Separation and Separation Review, visit the full article [[Separation and Separation Review|here]] | ||
| | | | ||
The '''Separation Review''' module was added to improve review of complicated document sets separated and classified by '''ESP Auto Separation'''. Because this Separation Provider separates using page based classification, it can be important to how it made the decision to separate or not separate a document on a page by page basis. The '''Classify Review''' module presents the reviewer with pages already placed in document folders, and it can be cumbersome to review the page by page separation viewing documents already placed in folders. | |||
This | Enter '''Separation Review'''. This review module is modeled off our '''ESP Auto Separation Tester''' which Grooper Architects use to test the separation and classification of documents, using '''ESP Separation'''. This viewer gives you a much broader look at the individual pages, allowing an easier (and ultimately quicker and more efficient) view of the separation logic applied to the batch. | ||
There are further quality of life improvements for the '''Separation Review''' module, making the process of reviewing documents separated and classified by '''ESP Auto Separation''' simpler, faster, and more satisfying. | |||
|} | |} | ||
Revision as of 11:51, 28 July 2020
| Getting Started | |||
|
Grooper is a software application that helps organizations innovate workflows by integrating difficult data. Grooper empowers rapid innovation for organizations processing and integrating large quantities of difficult data. Created by a team of courageous developers frustrated by limitations in existing solutions, Grooper is an intelligent document and digital data integration platform. Grooper combines patented and sophisticated image processing, capture technology, machine learning, and natural language processing. Grooper – intelligent document processing; limitless, template-free data integration. |
Getting Started | ||
| Install and Setup | |||
| 2.80 Reference Documentation | |||
| Featured Articles | Did you know? |
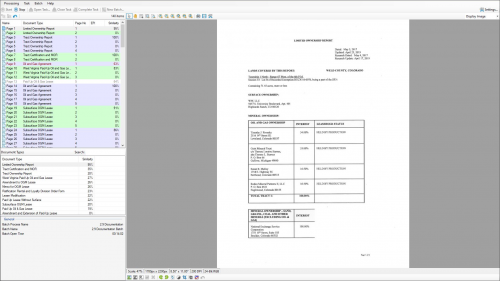 Grooper uses various approaches and algorithms to determine the classification of a page or folder. The settings on a Content Model and Document Type add to the complexities for separating pages into documents. Grooper Version 2.9 builds on the Separation settings found on Document Types, including the ability to adjust the Training Scope and configure a Secondary Page Extractor. Adjusting the Training Scope provides benefits to the accuracy and performance of ESP Auto Separation by focusing what is important when it comes time to separate and classify Unstructured paginated documents. For example, the Normal mode will create a single FormType and divide trained examples into "First", "Middle" and "Last" pages. From individual document to individual document, often the most meaningful features composing them are found on the first and last pages, and there can be more variance on the pages in between. This is different from the previous approach, which created individual FormTypes for each trained example, each with their own "Page X of X" PageType objects. This unifies all trained examples into a single FormType, making the training and classification of these documents ultimately simpler and more efficient. The FirstLast mode assumes meaningful features for classification are only found on the first and last pages, with the middle pages containing no information needed to make a separation or classification decision. With this mode enabled, only trained examples of the first and last page and their associated features will be saved. This can improve processing time by removing all the features in the middle pages for consideration. The FirstOnly mode narrows this scope even further by only storing features from the first page of trained documents. Furthermore, ESP Auto Separation removes but does not eliminate a lot of the manual work to separate and classify documents. Separation Review is a new review module designed to make the manual work quick and easy. For more information on Separation and Separation Review, visit the full article here |
The Separation Review module was added to improve review of complicated document sets separated and classified by ESP Auto Separation. Because this Separation Provider separates using page based classification, it can be important to how it made the decision to separate or not separate a document on a page by page basis. The Classify Review module presents the reviewer with pages already placed in document folders, and it can be cumbersome to review the page by page separation viewing documents already placed in folders. Enter Separation Review. This review module is modeled off our ESP Auto Separation Tester which Grooper Architects use to test the separation and classification of documents, using ESP Separation. This viewer gives you a much broader look at the individual pages, allowing an easier (and ultimately quicker and more efficient) view of the separation logic applied to the batch. There are further quality of life improvements for the Separation Review module, making the process of reviewing documents separated and classified by ESP Auto Separation simpler, faster, and more satisfying. |
| New in 2.9 | Featured Use Case | ||||||||||||||||||||||||||||||||||||
|

Discover how they:
| ||||||||||||||||||||||||||||||||||||







| Other Resources | |||
|
|||