
Main Page: Difference between revisions
Dgreenwood (talk | contribs) No edit summary |
Dgreenwood (talk | contribs) No edit summary |
||
| (19 intermediate revisions by 2 users not shown) | |||
| Line 12: | Line 12: | ||
|[[Install and Setup]] | |[[Install and Setup]] | ||
|-style="background-color:#fde6cb" valign="top" | |-style="background-color:#fde6cb" valign="top" | ||
|[ | |[https://grooper.bisok.com/Documentation/2.90/Main/HTML5/index.htm#t=Start_Page.htm 2.90 Reference Documentation] | ||
|} | |} | ||
| Line 21: | Line 21: | ||
|-style="background-color:#d8f3f1" valign="top" | |-style="background-color:#d8f3f1" valign="top" | ||
| | | | ||
<blockquote style="font-size:14pt"> | |||
[[Data Context]] | |||
</blockquote> | |||
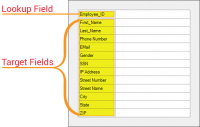
Data without context is meaningless. Context is critical to understanding and modeling the relationships between pieces of information on a document. Without context, it’s impossible to distinguish one data element from another. Context helps us understand what data refers to or “means”. | |||
This allows us to build an extraction logic using '''[[Data Type]]''' and '''[[Field Class]]''' extractors in order to build and populate a '''[[Data Model]]'''. | |||
There are three fundamental data context relationships: | |||
* '''Syntactic''' - Context given by the syntax of data. | |||
* '''Semantic''' - Context given by the lexical content associated with the data. | |||
* '''Spatial''' - Context given by where the data exists on the page, in relationship with other data. | |||
Using the context these relationships provide allows us to understand how to target data with extractors. | |||
| | | | ||
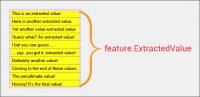
[[ | You can now manually manipulate the confidence of an extraction result. The '''''[[Confidence Multiplier and Output Confidence]]''''' properties of '''[[Data Type]]''' and '''[[Data Format]]''' extractors allow you to change the confidence score of extraction results. No longer are you forced to accept the score Grooper provides. These properties give you more control when it comes to what confidence a result ''should'' be. | ||
This allows you to prioritize certain results over others. You can create a kind of "fall back" or "safety net" result by using this property. You can even ''increase'' the confidence of an extractor's result, allowing you to give more weight to a fuzzy extractor's result over a non-fuzzy one, for example. | |||
For more information visit, the [[Confidence Multiplier and Output Confidence]] article. | |||
|} | |} | ||
| Line 75: | Line 73: | ||
|- | |- | ||
|[[Image:Cmis_lookup_002.png|center|200px|link=CMIS Lookup]] | |[[Image:Cmis_lookup_002.png|center|200px|link=CMIS Lookup]] | ||
|[[Image: | |[[Image:Content_type_filter_000.png|center|100px|link=Content Type Filter]] | ||
|[[Image:Output_extractor_key_000.png|center|200px|link=Output Extractor Key]] | |[[Image:Output_extractor_key_000.png|center|200px|link=Output Extractor Key]] | ||
|[[Image:box_cmis_binding_000.png|center|200px|link=Box (CMIS Binding)]] | |[[Image:box_cmis_binding_000.png|center|200px|link=Box (CMIS Binding)]] | ||
| Line 83: | Line 81: | ||
|style="text-align:center"|'''[[Output Extractor Key]]''' | |style="text-align:center"|'''[[Output Extractor Key]]''' | ||
|style="text-align:center"|'''[[Box (CMIS Binding)]]''' | |style="text-align:center"|'''[[Box (CMIS Binding)]]''' | ||
|- | |||
|colspan="4"|[[Image:Linq_to_grooper_objects_001.png|center|200px|link=LINQ to Grooper Objects]] | |||
|- | |||
|colspan="4" style="text-align:center"|'''[[LINQ to Grooper Objects]]''' | |||
|} | |} | ||
| | | | ||
[[File:American-airlines-credit-union-financial-services-document-data-capture-integration-grooper.jpg|400px|right|link=https://www.bisok.com/case-studies/electronic-data-discovery-case-study/]] | |||
<blockquote style="font-size:14pt"> | <blockquote style="font-size:14pt"> | ||
'''They’re Saving Over 5,000 Hours Every Year in Data Discovery and Processing''' | |||
</blockquote> | </blockquote> | ||
American Airlines Credit Union has transformed their data workflows, quickly saving thousands of hours in electronic data discovery , resulting in much greater efficiency and improved member services. | |||
Discover how they: | |||
* Quickly found 40,000 specific files among one billion | |||
* | * Easily integrated with data silos and content management systems when no other solution would | ||
* | * Have cut their mortgage processing time in half (and they process mortgages for 47 branch offices!) | ||
* | * Learn from the document and electronic data discovery experts at BIS! | ||
* | |||
[https://www.bisok.com/case-studies/ | [https://www.bisok.com/case-studies/electronic-data-discovery-case-study/ You can access the full case study clicking this link]. | ||
|} | |} | ||
| Line 122: | Line 119: | ||
* [http://grooper.bisok.com/Documentation/2.80/Main/HTML5/index.htm#t=Start_Page.htm 2.80 Reference Documentation] | * [http://grooper.bisok.com/Documentation/2.80/Main/HTML5/index.htm#t=Start_Page.htm 2.80 Reference Documentation] | ||
* [http://grooper.bisok.com/Documentation/2.80/SDK/HTML5/index.htm#t=Developer_Reference.htm 2.80 SDK Documentation] | * [http://grooper.bisok.com/Documentation/2.80/SDK/HTML5/index.htm#t=Developer_Reference.htm 2.80 SDK Documentation] | ||
* [https://grooper.bisok.com/Documentation/2.90/Main/HTML5/index.htm#t=Start_Page.htm 2.90 Reference Documentation] | |||
|style="width:25%"| | |style="width:25%"| | ||
* [https://blog.bisok.com/webinars Webinars and Video] | * [https://blog.bisok.com/webinars Webinars and Video] | ||
Revision as of 10:02, 23 September 2020
| Getting Started | |||
|
Grooper is a software application that helps organizations innovate workflows by integrating difficult data. Grooper empowers rapid innovation for organizations processing and integrating large quantities of difficult data. Created by a team of courageous developers frustrated by limitations in existing solutions, Grooper is an intelligent document and digital data integration platform. Grooper combines patented and sophisticated image processing, capture technology, machine learning, and natural language processing. Grooper – intelligent document processing; limitless, template-free data integration. |
Getting Started | ||
| Install and Setup | |||
| 2.90 Reference Documentation | |||
| Featured Articles | Did you know? |
|
Data without context is meaningless. Context is critical to understanding and modeling the relationships between pieces of information on a document. Without context, it’s impossible to distinguish one data element from another. Context helps us understand what data refers to or “means”. This allows us to build an extraction logic using Data Type and Field Class extractors in order to build and populate a Data Model. There are three fundamental data context relationships:
Using the context these relationships provide allows us to understand how to target data with extractors. |
You can now manually manipulate the confidence of an extraction result. The Confidence Multiplier and Output Confidence properties of Data Type and Data Format extractors allow you to change the confidence score of extraction results. No longer are you forced to accept the score Grooper provides. These properties give you more control when it comes to what confidence a result should be. This allows you to prioritize certain results over others. You can create a kind of "fall back" or "safety net" result by using this property. You can even increase the confidence of an extractor's result, allowing you to give more weight to a fuzzy extractor's result over a non-fuzzy one, for example. For more information visit, the Confidence Multiplier and Output Confidence article. |
| New in 2.9 | Featured Use Case | ||||||||||||||||||||||||||||||||||||
|

Discover how they:
| ||||||||||||||||||||||||||||||||||||







| Other Resources | |||
|
|||