
Main Page: Difference between revisions
Dgreenwood (talk | contribs) No edit summary |
Dgreenwood (talk | contribs) No edit summary |
||
| (13 intermediate revisions by the same user not shown) | |||
| Line 21: | Line 21: | ||
|-style="background-color:#d8f3f1" valign="top" | |-style="background-color:#d8f3f1" valign="top" | ||
| | | | ||
[[File:Table-extraction-simple-table.png|thumb|300px|Data in an Excel spreadsheet is an example of tabular data.]] | |||
<blockquote style="font-size:14pt"> | <blockquote style="font-size:14pt"> | ||
[[ | [[Table Extraction]] | ||
</blockquote> | </blockquote> | ||
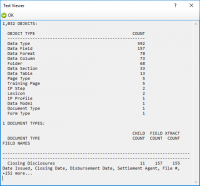
Table Extraction refers to Grooper's functionality to extract data from cells in tables. This is accomplished by configuring the '''[[Data Table]]''' '''''[[Data Element]]''''' in a '''[[Data Model]]'''. | |||
Tables are one of the most common ways data is organized on documents. Human beings have been writing information into tables before they started writing literature, even before paper was invented. There are examples of tables carved onto the walls of Egyptian temples! They are excellent structures for representing a lot of information with various characteristics in common in a relatively small space (or an Egyptian temple sized space). However, targeting the data inside them presents its own set of challenges. A table’s structure can range from simple and straightforward to more complex (even confounding). Different organizations may organize the same data differently, creating different tables for what, essentially, is the same data. | |||
In Grooper, tabular data can be extracted to '''Data Table''' objects using the ''[[Row Match (Table Extract Method)|Row Match]]'', ''[[Header-Value (Table Extract Method)|Header-Value]]'', or ''[[Infer Grid (Table Extract Method)|Infer Grid]]'' table extraction methods. | |||
| | | | ||
The earliest examples of OCR (Optical Character Recognition) can be traced back to the 1870s | The earliest examples of OCR (Optical Character Recognition) can be traced back to the 1870s. Early OCR devices were actually invented to aid the blind. This included "text-to-speech" devices that would scan black print and produce sounds a blind person could interpret, as well as "text-to-tactile" machines which would convert luminous sensations into tactile sensations. Machines such as these would allow a blind person to read printed text not yet converted to Braille. | ||
The first business to install an OCR reader was the magazine ''Reader's Digest'' in 1954. The company used it to convert typewritten sales reports into machine readable punch cards. | The first business to install an OCR reader was the magazine ''Reader's Digest'' in 1954. The company used it to convert typewritten sales reports into machine readable punch cards. | ||
Revision as of 12:19, 22 February 2021
| Getting Started | |||
|
Grooper was built from the ground up by BIS, a company with 35 years of continuous experience developing and delivering new technology. Grooper is an intelligent document processing and digital data integration solution that empowers organizations to extract meaningful information from paper/electronic documents and other forms of unstructured data. The platform combines patented and sophisticated image processing, capture technology, machine learning, natural language processing, and optical character recognition to enrich and embed human comprehension into data. By tackling tough challenges that other systems cannot resolve, Grooper has become the foundation for many industry-first solutions in healthcare, financial services, oil and gas, education, and government. |
Getting Started | ||
| Install and Setup | |||
| 2.90 Reference Documentation | |||
| Featured Articles | Did you know? |
 Table Extraction refers to Grooper's functionality to extract data from cells in tables. This is accomplished by configuring the Data Table Data Element in a Data Model. Tables are one of the most common ways data is organized on documents. Human beings have been writing information into tables before they started writing literature, even before paper was invented. There are examples of tables carved onto the walls of Egyptian temples! They are excellent structures for representing a lot of information with various characteristics in common in a relatively small space (or an Egyptian temple sized space). However, targeting the data inside them presents its own set of challenges. A table’s structure can range from simple and straightforward to more complex (even confounding). Different organizations may organize the same data differently, creating different tables for what, essentially, is the same data. In Grooper, tabular data can be extracted to Data Table objects using the Row Match, Header-Value, or Infer Grid table extraction methods. |
The earliest examples of OCR (Optical Character Recognition) can be traced back to the 1870s. Early OCR devices were actually invented to aid the blind. This included "text-to-speech" devices that would scan black print and produce sounds a blind person could interpret, as well as "text-to-tactile" machines which would convert luminous sensations into tactile sensations. Machines such as these would allow a blind person to read printed text not yet converted to Braille. The first business to install an OCR reader was the magazine Reader's Digest in 1954. The company used it to convert typewritten sales reports into machine readable punch cards. It would not be until 1974 that OCR starts to form as we imagine it now with Ray Kurzweil's development of the first "omni-font" OCR software, capable of reading text of virtually any font. |
| New in 2.9 | Featured Use Case | ||||||||||||||||||||||||||||||||||||
|

Discover how they:
| ||||||||||||||||||||||||||||||||||||







Feedback
| Feedback | |
|
|
We value your feedback! |

| Other Resources | |||
|
|||