
Main Page
| Getting Started | |||
|
Grooper is a software application that helps organizations innovate workflows by integrating difficult data. Grooper empowers rapid innovation for organizations processing and integrating large quantities of difficult data. Created by a team of courageous developers frustrated by limitations in existing solutions, Grooper is an intelligent document and digital data integration platform. Grooper combines patented and sophisticated image processing, capture technology, machine learning, and natural language processing. Grooper – intelligent document processing; limitless, template-free data integration. |
Getting Started | ||
| Install and Setup | |||
| 2.90 Reference Documentation | |||
| Featured Articles | Did you know? |
 Labeled OMR is an extractor used to output OMR checkbox labels. It determines whether labeled checkboxes are checked or not and, if checked, outputs the label as its result. Documents use checkboxes to make our life easier. They are particularly prevalent on structured forms. It gives the person filling out the form the ability to just check a box next to a series of options rather than typing in the information. However, most of Grooper's extraction centers around regular expression, matching text patterns and returning the result. There isn't necessarily a character to match a checked checkbox. Regular expression isn't going to cut it to determine if a box is checked or not. This is where OMR comes into play. OMR stands for "Optical Mark Recognition". OMR determines checkbox states. The basic idea behind it is very simple. First find a box. A box is just four lines connected to each other in a square-like fashion. If that box has a mark of some kind inside it, it is checked. If not, it's not. Checked (or marked) boxes, whether a checked "x" (☒), a checkmark (☑), or a check block (▣), while have more black pixels inside the box than an unchecked (or unmarked) one (☐). If the detected box has a high threshold of black pixels in it, it's checked (or marked). If not, it's unchecked (or unmarked). |
The earliest examples of OCR (Optical Character Recognition) can be traced back to the 1870s? Early OCR devices were actually invented to aid the blind. This included "text-to-speech" devices that would scan black print and produce sounds a blind person could interpret, as well as "text-to-tactile" machines which would convert luminous sensations into tactile sensations. Machines such as these would allow a blind person to read printed text not yet converted to Braille. The first business to install an OCR reader was the magazine Reader's Digest in 1954. The company used it to convert typewritten sales reports into machine readable punch cards. It would not be until 1974 that OCR starts to form as we imagine it now with Ray Kurzweil's development of the first "omni-font" OCR software, capable of reading text of virtually any font. |
| New in 2.9 | Featured Use Case | ||||||||||||||||||||||||||||||||||||
|

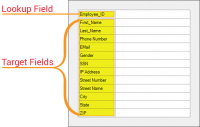
Discover how they:
| ||||||||||||||||||||||||||||||||||||







Feedback
| Feedback | |
|
|
We value your feedback! |
| Other Resources | |||
|
|||