
Main Page
| Getting Started | |||
|
Grooper is a software application that helps organizations innovate workflows by integrating difficult data. Grooper empowers rapid innovation for organizations processing and integrating large quantities of difficult data. Created by a team of courageous developers frustrated by limitations in existing solutions, Grooper is an intelligent document and digital data integration platform. Grooper combines patented and sophisticated image processing, capture technology, machine learning, and natural language processing. Grooper – intelligent document processing; limitless, template-free data integration. |
Getting Started | ||
| Install and Setup | |||
| 2.90 Reference Documentation | |||
| Featured Articles | Did you know? |
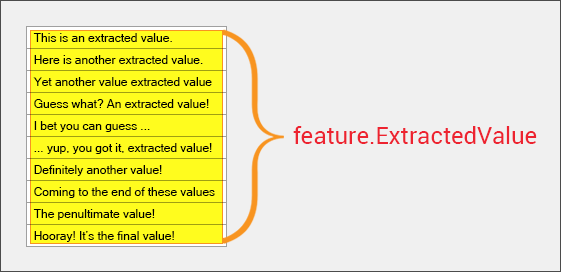 Output Extractor Key is a property on a the Data Type extractor. It is exposed when the Collation property is set to Individual. When the Output Extractor Key is set to True, each output value will be set to a key representing the name of the extractor which produced the match. It is useful when extracting non-word classification features.
|
You can now manually manipulate the confidence of an extraction result. The Confidence Multiplier and Output Confidence properties of Data Type and Data Format extractors allow you to change the confidence score of extraction results. No longer are you forced to accept the score Grooper provides. These properties give you more control when it comes to what confidence a result should be. This allows you to prioritize certain results over others. You can create a kind of "fall back" or "safety net" result by using this property. You can even increase the confidence of an extractor's result, allowing you to give more weight to a fuzzy extractor's result over a non-fuzzy one, for example. For more information visit, the Confidence Multiplier and Output Confidence article. |
| New in 2.9 | Featured Use Case | ||||||||||||||||||||||||||||||||||||
|

Discover how they:
| ||||||||||||||||||||||||||||||||||||







| Other Resources | |||
|
|||